Consider the following definition of a lexical token id for an identifier in a programming language, using extended regular expressions:
letter → [A-Za-z]
digit → [0-9]
id → letter (letter | digit)∗
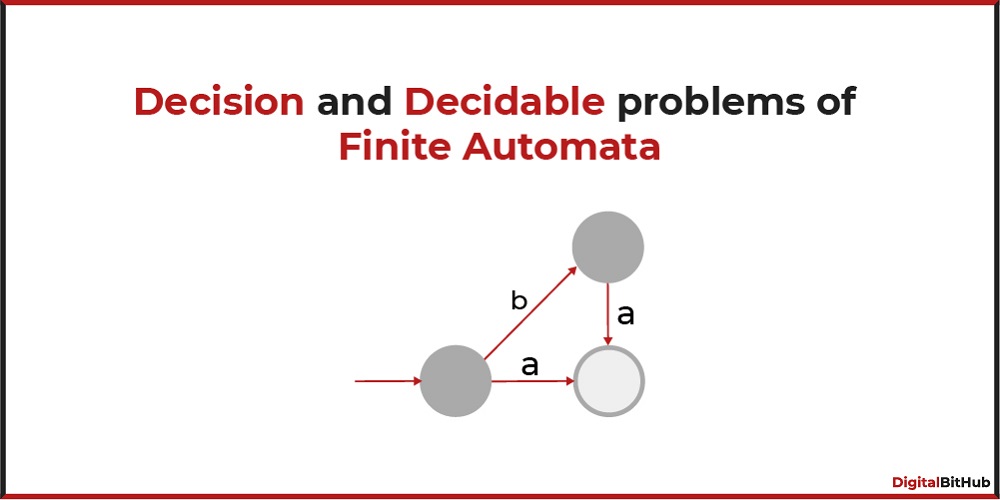
Which one of the following Non-deterministic Finite-state Automata with ε-transitions accepts the set of valid identifiers? (A double-circle denotes a final state)




Valid identifiers should start with a letter and followed by either a letter or a digit.
(A) The first option is wrong because as per NFA given, the identifier can start with a digit.
(B) Second option is wrong because this NFA gives the identifier as letter(letter)* or letter(digit)*
(C) The third option is correct it gives the correct regular expression as per the given grammar, letter (letter/digit)*
(D) Fourth option is wrong because this NFA doesn’t accept regular expression, letter(letter)*